Generating a relation model
When translating a semantic model to a relational model, there are three 'problems' which need to be resolved:
- Translate the object and attribute names for use in the target database
- Translate semantic relations into foreign key columns and constraints
- Translate the semantic concepts for specializations
For all kind of reasons the mapping of the semantic object/attribute name will not always be one-to-one with the original name in the semantic model. For this reason Semanta Modeler has some options to convert the names, which can be configured in the Model properties window (SQL settings tab).

The left side of this window shows three options to influence the naming:
Object name prefix: Prefix each created table with a specific prefix.
Add object shortname as attribute prefix: Each created object in the model can/will have a short name (typically a 3 character abbreviation of the object name). This option will use this as a prefix for each generated column.
Always use column prefixes from generalisation: When using specializations the prior option, the specialization attributes will get the prefix from the specialization they belong to. With this option, it is possible to get the generalization prefix on the specialization attributes.
Ad2: Translate semantic relations into foreign key columns and constraints
The concept of a relation in a semantic model should will be converted to the concept of a foreign key in the relational database. For this purpose the relation model generator will create a foreign key column in the table corresponding to each primary key column in the table being referenced. The naming of these foreign key columns can be configured in the right side of the SQL settings tab of the Model properties window (shown above).
The foreign key column mapping can be configured with a number of options, and offers a quite flexible way of naming your relational columns. The settings provided here are at model level, so will be valid for all foreign keys in the model. In addition to these settings, Semanta Modeler has an option to override the settings at a specific foreign key level.

Ad3: Translate the semantic concepts for specializations
The concepts specialization and generalization are typically not supported by a relational database. For this reason Semanta Modeler has a mapping algorithm which maps the specializations in your model to the relational model. The mapping comes down to the following:
- The relational database will only have tables for the generalizations
- A specialization block will translate to a column in the generalization table of type string, and a check constraint to allow for the possible short names of the specialization.
- All attributes for the specialization are added as optional columns to the table of the generalization. To distinguish between these columns, the names will be prefixed with either the short name or full name of the specialization object.
- When a record is of a specialization of a specific type, all mandatory columns of that specialization should have a value. A trigger will be generated to check for mandatory columns in the specialization when needed. This trigger will also guard foreign keys to specializations to only allow references to records of the correct type.
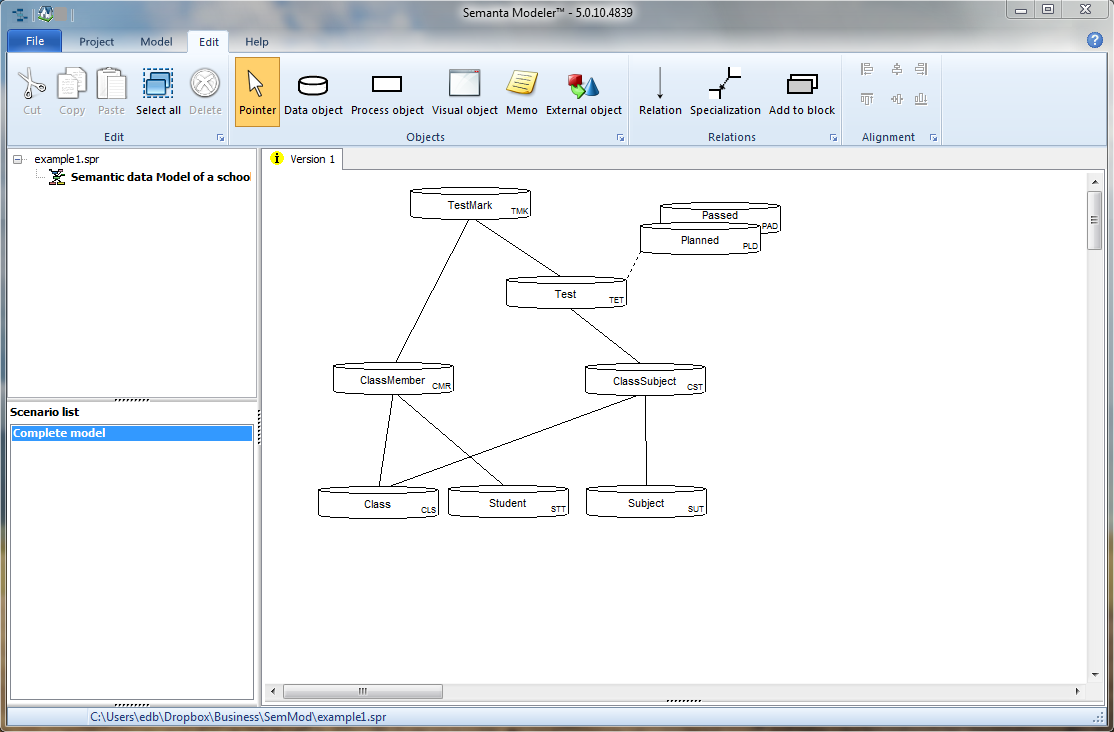
For example this model:

Translates into this relational table (for Microsoft SQL server):
create table dbo.Person (
PEN_Id int identity(1, 1) not null
,PEN_Name varchar(40) not null
,PEN_Employment varchar(3) not null
,constraint sc_PEN_Employment check (PEN_Employment in ('EME', 'UND'))
,EME_Salary float null
,constraint pk_Person primary key (PEN_Id)
)
Or this (using different SQL settings):
create table dbo.Person (
Id int identity(1, 1) not null
,Name varchar(40) not null
,Employment varchar(3) not null
,constraint sc_PEN_Employment check (Employment in ('EME', 'UND'))
,Employee_Salary float null
,constraint pk_Person primary key (Id)
)
Using this kind of specialization mapping (into the generalization), the specialization concept is especially useful for the modelling of a type or kind field into a record, which toggles a mandatory check on a set of columns.
Data type mapping
When generating a relation database from the definition in Semanta Modeler, we quickly run against the different implementations for the different target databases. One of these differences is the mapping of the data types. The table below shows how the different data types known to Semanta Modeler are mapped against the target database:
The script generator uses the type mappings to generate the scripts. In addition to plain attributes, the semantic model can contain additional attribute types (which have a special meaning). These attributes are the specialization block and the relation. These two attributes require the special handling as described earlier (when translating to the relational model) as these concepts are unknown or different in the world of a relational database.
Generated output scripts
Before generating the database scripts, Semanta Modeler will check the consistency of the model. When errors are found, the export cannot proceed. You can trigger the consistency check manually by using the Check model option from the Model toolbar. This check can generate errors, warnings and hints in order to guide you in creating a correct database model.
Once the model is found to be correct, we can start the generation of scripts. When generating scripts for a full database (creating a new database from scratch), Semanta Modeler will generate a number of scripts for you (which scripts are available also depend on the choosen target database, as not each database supports all concepts):

These scripts contain the following:
- Create table script: This script contains the DDL statements for the creation of all tables in the model (as described above).
- Create index script:This script contains the DDL statements for the creation of additional indexes which have been defined in the model. In addition it will automatically include an index on every foreign key and specialization block in the model (when not defined in the model).
- Create view script: This script contains the DDL statements for the creation of database views for each of the specializations in the model. Each view is defined as a selection on the generalization table, with a filter on the specialization block field. It will also only contain the columns applicable to the specialization.
- Create triggers script:This script contains the code to guard the specialization's mandatory fields and the relations to specializations (as described above).
- Create sequences script: This script contains the DDL statements for the creation of database sequence objects. When attributes in the domain have been defined to be auto-incrementing, some database implementations need a sequence object to generate the numbers for these fields. Semanta Modeler will create a sequence for each auto-incrementing field in the model.
- Create comments script:This script contains the code to add the object and attribute comments from the model on the target database DDL. After running this script, a database DBA or developer can see the model comments in tools like Oracle SQL developer or Microsoft SQL Server Management Studio.
- Create sample data script: This script contains INSERT statements for demo data which has been entered as part of the model.
Full script export versus version migration
When generating a database script, Semanta Modeler offers the option to generate scripts for creating a new database, or to generate a migration script between two versions of the model (so it will migrate the existing database to the new version of the model). Using the latter scripts, it is possible to apply changes to the model to an existing database.
The assumption for the migration script will always be that the current state of the database is 100% equal to the scripts generated by Semanta Modeler for the old version. The aim of the migration scripts is to maintain the existing data as much as possible. As these kind of migrations can become quite complex, not all situations can be handled, but the script attempts to give a very useful starting point.
The basis for the version migration is formed by the version compare tool (which is also available as a report in the semantic modeler). The migration script generator will combine the version differences (as found by the version compare tool) with the generated relation model, and generate the necessary DDL statements to update the target database.
A last useful tip: breaking a complex migration into several smaller steps (using multiple intermediate versions), will increase the ability of Semanta Modeler to generate a correct migration automatically for you.