From version 5.1.6.4908 on, Cordys Crom support is available in Semanta Modeler.
Crom stands for Cordys Relational Object Mapping, and provides o/r mapping on top of WS-AppServer. See the Cordys Community for more details of Crom.
The support given by Semanta Modeler is in generating XML files per domain model/DB table, which content can be used to copy and paste in the WS-AppServer Package of the domain model of your project.
This article describes how Cordys Crom support can be used, based om the Ticket project, also used in the articles on Crom on the Cordys Community.
Crom - Child Model
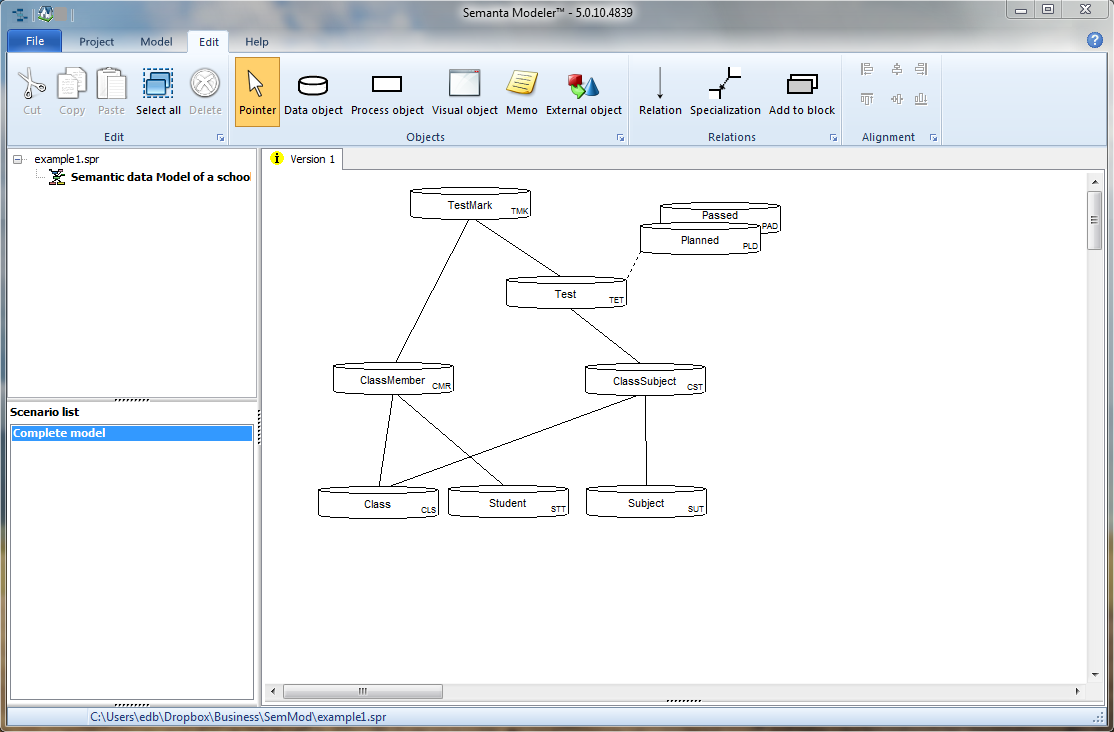
The assumption is that the DB Model of your project is already modeled in Semanta Modeler.

Crom support is possible by defining a Child Model of type Crom:

From the dialog chose as Child Model type 'Crom':

The description you give is the namespace used in the generated XML, when referring to other models/DB tables:

For example:
<Ticket>
<Solution>TicketDomainModel::Solution</Solution>
</Ticket>

Right click on the Crom child model in the child model tree and select 'Edit child model'.

Selecting all objects will result in a Crom model that is similar to the DB model:

Note that the objects 'SolutionRevision' and 'Project_Person' have been given different colors.
The reason is that they implement the Revision and List design pattern, being explained in more detail in the next text.
Edit object details
By double clicking an object, the details of the object can be changed, making it possible to define the domain model as desired.
These details are copied from the DB model. Changes made to the DB Model after having created the Crom child model, will also be copied.
Double clicking for example the 'Component' object results in:

The 'Name' attribute is being selected in this example.
Here we see the attribute's properties.
Some of these properties are inherited from the DB model and can be changed (e.g. 'Primary key attribute') or can not be changed (e.g. 'Name', 'DataType').
Other properties are Crom child model specific (e.g. 'Exclude from domain', 'Transient').
Attributes that implement relations (DataType = 'ForeignKey') to other objects have quit a lot more properties. Clicking the 'Ticket' object, with the 'Component' attribute select will give:

The extra properties are in 3 groups:
- Relation direction down properties (Its), e.g. the Component the Ticket refers to.
- Relation direct up properties (All Its), e.g. all Tickets that refer to the same Component.
- Inherited properties (Roles). These are not editable, but shown for giving extra information.
These custom attributes can be delete when not needed anymore. Attributes that are inherited from the DB Model can not be deleted.
Common attribute properties
Domain
The name of the Crom object. The default is the value of the DB table name, but it can be overruled.
An example of XML output:
<Ticket>
<Id unique="true">i4</Id>
<Description>string</Description>
...
</Ticket>
Name
This is the name of the attribute, being read only.
If inherited from the DB model, it has the same value as the DB table attribute.
For custom attributes, it has the same value as the 'Attr Domain' property.
It is not used for generating output.
DataType
The data type. Read only for inherited attributes.
An example of XML output:
<Ticket>
<Id unique="true">i4</Id>
<Description>string</Description>
...
</Ticket>
Primary key attribute
Indicates this attribute is part of the primary key.
An example of XML output:
<Ticket>
<Id unique="true">i4</Id>
<Description>string</Description>
...
</Ticket>
Attr Domain
This is the Crom name of the attribute.
An example of XML output:
<Ticket>
<Id unique="true">i4</Id>
<Description>string</Description>
...
</Ticket>
Exclude from domain
When checked, the attribute is not in the output.
Transient
Often used for custom attributes, to indicate the value does not need to be persisted.
An example of XML output:
<Ticket>
<Id unique="true">i4</Id>
<Description>string</Description>
<TotalNotes persistence="1">i4</TotalNotes>
...
</Ticket>
Foreign Key properties - Its relation
FK Implementation
This dropdown property indicates how the Foreign Key Its relation is implemented.
There are 3 possible values:
FK Field
The Foreign Key fields are in the output.
An example of XML output:<Ticket>
...
<Component>i4</Component>
...
</Ticket>
Nest the relation
The object being referred is nested as a type into the object.
An example of XML output:<Ticket>
...
<Component>TicketDomainModel::Component</Component>
...
</Ticket>
Adopt the relation
Used in the List link object to indicate that the linked object's attributes have to be attributes of the List object.
An example of XML output for the object 'Project':<Project>
...
<User occ="*">TicketDomainModel::User</User>
...
</Project>
which is the result of the combination of properties on the Foreign Key attributes 'Project' and 'Person' in the linking object 'Project_Person'.
'Project_Person.Person' has the property 'FK implementation' set to 'Adopt the relation'
'Project_Person.Project' has the property 'Next the All Its relation' checked
All Its Attr Domain
This is the Crom attribute name for the All Its relation in case the property 'Nest the All Its Relation' is checked.
An example of XML output for the object 'Ticket':
<Ticket>
...
<Solution>TicketDomainModel::Solution</Solution>
...
</Ticket>
Exclude from All Its domain
When checked, the attribute is not in the output of the object, which is referred.
Force 1:1 Relation
This property removes the 'occ="*"'' attribute in the XML tag in case
This property removes the 'occ="*"'' attribute in the XML tag in case
Next the All Its Relation
To implement the Revision design pattern, this property should stay unchecked.
An example of XML output for the object 'Solution':
<Solution>
<Id unique="true">i4</Id>
<Description unique="true">string</Description>
<CreatedOn>dateTime</CreatedOn>
<Solver>TicketDomainModel::User</Solver>
<Project>TicketDomainModel::Project</Project>
</Solution>
To implement the Revision design pattern, this property should stay unchecked.
An example of XML output for the object 'Solution':
<Solution>
<Id unique="true">i4</Id>
<Description unique="true">string</Description>
<CreatedOn>dateTime</CreatedOn>
<Solver>TicketDomainModel::User</Solver>
<Project>TicketDomainModel::Project</Project>
</Solution>
where the property 'Exclude from All Its Domain' and 'Next the All Its Relation' are unchecked in the SolutionRevision object.
Foreign Key properties - Roles
Role name
This shows the role name of the Its Relation (if given). This is defined in the DB Model and read only.
Role name
This shows the role name of the All Its Relation (if given). This is defined in the DB Model and read only.
This shows the role name of the All Its Relation (if given). This is defined in the DB Model and read only.
Crom Export
Once all attribute properties are set, an export can be made, generating an XML file for each domain object.

To start the export wizard, select the 'Project' tab and click the 'Export' button. From the
dropdown menu select 'Crom Domain XML schema'. This will result in launching the export wizard.

Just click next here.

Fill in a path to the folder where you like to have the export result.
Also chose the child model to export.

Clicking 'Finish' will start de XML file generation.

The files have been generated when you see this message.
For the Ticket domain model, these are file XML files that are generated:

<Component>
<Id unique="true">i4</Id>
<Name>string</Name>
<Description>string</Description>
<Component.Component occ="*">TicketDomainModel::Ticket</Component.Component>
</Component>
The content of these XML files can be copied in the WS-AppServer Package in Cordys.
Each time a change was made to the DB Model, the Crom domain model needs to be updated and exported also.
Using a file version management system, the changed XML files will be easy to detect.
<Name>string</Name>
<Description>string</Description>
<Component.Component occ="*">TicketDomainModel::Ticket</Component.Component>
</Component>
<Note>
<Id unique="true">i4</Id>
<Description>string</Description>
<CreatedOn>dateTime</CreatedOn>
<User>TicketDomainModel::User</User>
</Note>
<Project>
<Id unique="true">i4</Id>
<Name>string</Name>
<Description>string</Description>
<User occ="*">TicketDomainModel::User</User>
</Project>
<Solution>
<Id unique="true">i4</Id>
<Description>string</Description>
<CreatedOn>dateTime</CreatedOn>
<Solver>TicketDomainModel::User</Solver>
<Project>TicketDomainModel::Project</Project>
</Solution>
<Ticket>
<Id unique="true">i4</Id>
<Description>string</Description>
<Summary>string</Summary>
<Severity>string</Severity>
<Priority>string</Priority>
<CreatedOn>dateTime</CreatedOn>
<LastModified>dateTime</LastModified>
<Reporter>TicketDomainModel::User</Reporter>
<Project>TicketDomainModel::Project</Project>
<Component>TicketDomainModel::Component</Component>
<Assignee>TicketDomainModel::User</Assignee>
<Note occ="*">TicketDomainModel::Note</Note>
<Solution>TicketDomainModel::Solution</Solution>
</Ticket>
<User>
<Id unique="true">i4</Id>
<Name>string</Name>
<Email>string</Email>
<MappingColumn1>dateTime</MappingColumn1>
<MappingColumn2>boolean</MappingColumn2>
</User>
Each time a change was made to the DB Model, the Crom domain model needs to be updated and exported also.
Using a file version management system, the changed XML files will be easy to detect.